Overview of Emotion Models¶
How to define emotion or affect?¶
Categorical Model¶
| Tomkins | Izard | Plutchik | Ortony | Ekman |
|---|---|---|---|---|
| Joy | Enjoyment | Joy | Joy | Happiness |
| Anguish | Sadness | Sorrow | Sadness | Sadness |
| Fear | Fear | Fear | Fear | Fear |
| Anger | Anger | Anger | Anger | Anger |
| Disgust | Disgust | Disgust | Disgust | Disgust |
| Surprise | Surprise | Surprise | Surprise | Surprise |
| Interest | Interest | Acceptance | ||
| Shame | Shame | Anticipation | ||
| Shyness | ||||
| Guilt |
Dimensional Model¶
| valence (positive/negative) | arousal (excited/calm) | dominance (feeling control/not) | |
|---|---|---|---|
| neutral | 5 | 5 | 5 |
| fear | 3.2 | 5.92 | 3.6 |
| joy | 7.4 | 5.73 | 6.2 |
| sadness | 3.15 | 4.56 | 4 |
| anger | 2.55 | 6.60 | 5.05 |
Datasets¶
SemEval-2007 "Affective Text"¶
1200 headlines, Ekman categories, scores from 0 to 100, variance
<instance id="1">Mortar assault leaves at least 18 dead<instance>
| id | anger | disgust | fear | joy | sadness | surprise |
|---|---|---|---|---|---|---|
| 1 | 22 | 2 | 60 | 0 | 64 | 0 |
Other:
SentiWordNet polarity (positive, negative, objective)
WordNet Affect(not public, but...) Hierarchycal emotions, can be flattened to near-traditional categories
ANEW (Affective Norm of English Words) - normative dimensional emotional ratings of 14,000 English words. Exists analogous researches and datasets for many languages with the same dimensions.
Methods and architecture¶
Vector Space Model (VSM) on categorical emotions¶
As training data we use documents marked with emotion categories labels.
Similarity in terms of bag of words and Tf-Idf.
For input query (document) we find n most similar documents and use mean of their emotion labels as a result.
TexEmo project relies on this technique. But no real results or solutions from this project, only paper.
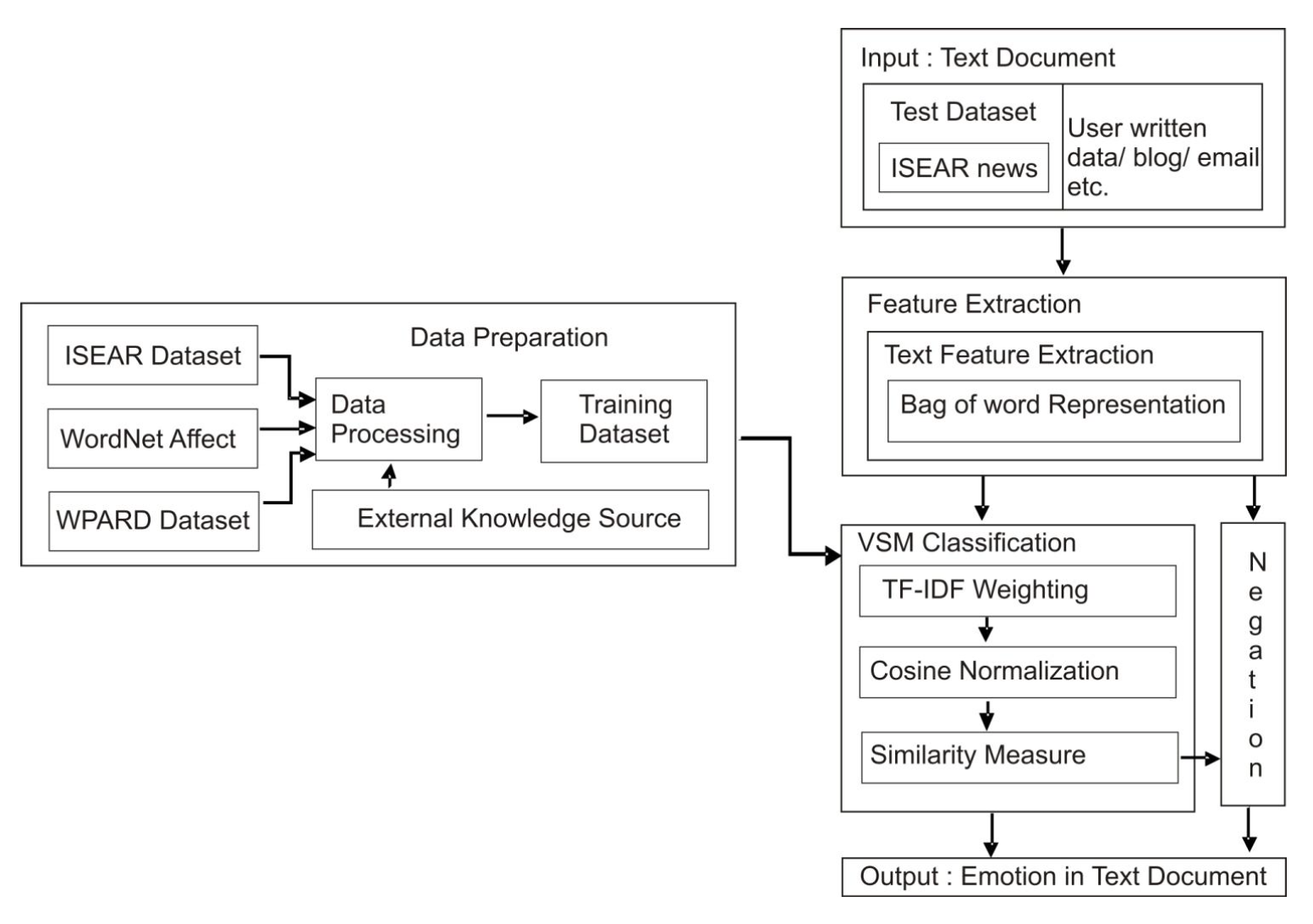
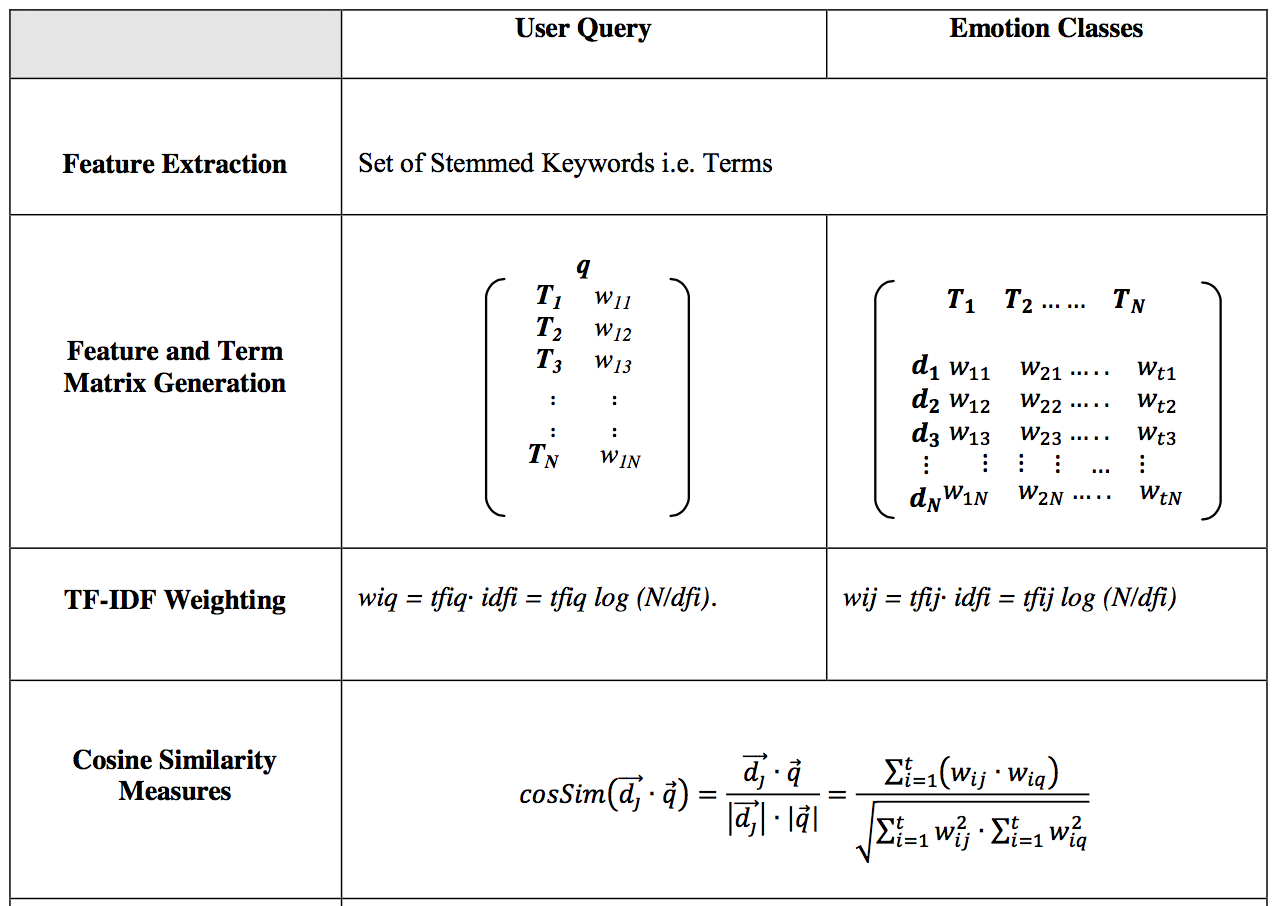 wiq = tfiq * idfi; wid = tfid * idfi;
wiq = tfiq * idfi; wid = tfid * idfi;
tfi(q or d): frequency of a term i in document d or query q;
idfi = Inverse document frequency: measures the rarity of a term i in all documents.
Three-dimensional estimation model¶
\begin{aligned}
\overline{w} = (valence, arousal, dominance) = ANEW(w)\text{, w - word}
\end{aligned}
To increase ANEW size we can use synonims from WordNet dataset.
Take synonims for keyword, Valence-Arousal-Dominance metric for each synonim from ANEW and produce mean from synonims on each dimension as a result keyword value.
\begin{aligned}
\overline{emotion} = \frac{\sum_{i=1}^{k}\overline{w}}{k}\text{, k - keyword's synonims count}
\end{aligned}
Latent Symantic Analysis / Indexing (LSA/LSI)¶
Let's take newspapers headlines:
- British police know the whereabouts of the founder of Wikileaks
- In the US court begins trial against the Russians who sent spam
- Nobel Peace Prize award ceremony boycotted 19 countries
- In the UK arrested the founder of the website Wikileaks Julian Assange
- Ukraine ignores the Nobel Prize award ceremony
- A Swedish court has refused to hear an appeal of the founder of Wikileaks
- NATO and the US have developed plans for the defense of the Baltic countries against Russia
- UK police found the founder of Wikileaks, but not arrested
- In Stockholm and Oslo today will be awarded the Nobel Prize
Words that occur more than once are highlighted
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | T9 | |
|---|---|---|---|---|---|---|---|---|---|
| wikileaks | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| arrested | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| UK | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| award | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| Nobel | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| founder | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| police | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| prize | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| against | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| countries | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| court | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| US | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| ceremony | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
Singular value decomposition (SVD)¶
Factorization of m × n matrix $M = U\Sigma V^*$
$\Sigma$ is a m × n diagonal matrix with non-negative real numbers on the diagonal. The diagonal entries $\sigma_i$ of $\Sigma$ are known as the singular values of M.
Image('data/Emotional_Analysis/svd.png', width=1000, height=800)

Truncated SVD¶
Image('data/Emotional_Analysis/svd_truncated.png', width=1000, height=600)

fig = plt.figure(figsize=(10,10))
words = [((0.57, -0.01), "wikileaks + founder", (-0.06, 0.01)),
((0.34, -0), "arrested + UK", (0, 0.02)),
((0, 0.52), "award + prize + Nobel", (0.01, 0.01)),
((0.31, -0), "police", (-0.01, -0.03)),
((0, 0.52), "award", (0.01, 0.01)),
((0.02, 0.03), "against", (0.01, 0.01)),
((0.01, 0.22), "countries", (0.01, 0.01)),
((0.12, 0.01), "court", (0.01, 0.01)),
((0.02, 0.01), "US", (0, -0.02)),
((0, 0.38), "ceremony", (0.01, 0.01))]
documents = [((0.43, -0), "T1", (0.01, -0.02)),
((0.05, 0.02), "T2", (0.01, -0.01)),
((0.01, 0.65), "T3", (0.01, 0.01)),
((0.54, -0.01), "T4", (0, -0.03)),
((0, 0.59), "T5", (0.01, 0.01)),
((0.37, -0), "T6", (0.01, -0.02)),
((0.01, 0.09), "T7", (0.01, 0.01)),
((0.63, -0.01), "T8", (0, -0.03)),
((0, 0.47), "T9", (0.01, 0.01))]
for word_plot_info in words:
plt.scatter(word_plot_info[0][0], word_plot_info[0][1], color='blue')
plt.annotate(word_plot_info[1], xy=tuple(map(operator.add, word_plot_info[0], word_plot_info[2])),
color='blue', size='16')
for doc_plot_info in documents:
plt.scatter(doc_plot_info[0][0], doc_plot_info[0][1], color='orange')
plt.annotate(doc_plot_info[1], xy=tuple(map(operator.add, doc_plot_info[0], doc_plot_info[2])),
color='orange', size='16')
plt.plot([0.3, 0.3], [-1, 1], color='red')
plt.plot([-1, 1], [0.3, 0.3], color='red')
plt.axis([-0.1, 0.8, -0.1, 0.7])
plt.show()

Non-Negative Matrix Factorization (NMF)¶

What's wrong with dimension reduction models?¶
- They are working with document labels.
- They select most similar document for input test query.
- So, to have fine emotional classification - we need to have document with high similarity in our test set for each query.
- We need to have really large train dataset.
- This methods require extremely careful selection of train dataset, because they are unsupervised and can't learn to separate emotions - they just make document-terms matrix factorisation.
- So... NON-PROFIT!
- Looks like pure dimension reduction models good only for classification of sentences like newspapers headlines or sentences from fairytails.
- They require documents about the same size.
- Hard to understand what's going on in SVD. You will not understand what singular vector means.
Word-based models problems¶
All this methods absolutely not take into account text semantic structure, when methods based on sentences/fragments can take in account some language structures.
For example, “I laughed at him” and “He laughed at me” would suggest different emotions from the first person’s perspective.
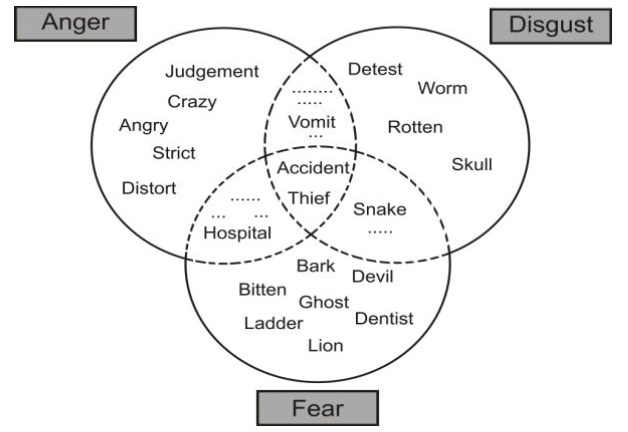
Absence of semantic structure leads and connected with second problem: words ambiguity.
Main paper references¶
Evaluation of Unsupervised Emotion Models to Textual Affect Recognition